Example – Sort
This is the first example in this chapter of a procedure. It takes a sentence and returns a sentence with the same words in alphabetical order. I partially figured out how it works myself after reading some of the chapter. The only slightly tricky part was earliest-helper. remove-once is from a previous chapter.
|
1
2
3
4
5
|
(define (remove-once wd sent)
(cond ((empty? sent) '())
((equal? wd (first sent)) (bf sent))
(else (se (first sent) (remove-once wd (bf sent))))))
|
|
1
2
3
4
5
6
|
(define (earliest-helper so-far rest) ; so-far refers to earliest word at current point
(cond ((empty? rest) so-far) ; if rest is empty then so-far was the earliest word
((before? so-far (first rest))
(earliest-helper so-far (bf rest)))
(else (earliest-helper (first rest) (bf rest)))))
|
|
1
2
3
|
(define (earliest-word sent)
(earliest-helper (first sent) (bf sent)))
|
|
1
2
3
4
5
6
7
|
(define (sort sent)
(if (empty? sent)
'()
(se (earliest-word sent) ;
(sort (remove-once (earliest-word sent) sent)))))
; above line calls sort w/ first word removed from sentence
|
Example – From-Binary
We want to take a word of ones and zeros, representing a binary number, and compute the numeric value that it represents. Each binary digit (or bit) corresponds to a power of two, just as ordinary decimal digits represent powers of ten. So the binary number 1101 represents (1×8)+(1×4)+(0×2)+(1×1) = 13. We want to be able to say
|
1
2
3
4
5
6
7
8
|
> (from-binary 1101)
13
> (from-binary 111)
7
|
Here was my solution
|
1
2
3
4
5
6
7
|
(define (from-binary num)
(cond ((empty? num) 0)
((= 1 (first num))
(+ (expt 2 (- (count num) 1))
(from-binary (bf num))))
(else (from-binary (bf num)))))
|
In english:
Base case: if num is empty, return 0.
Recursive case: if the first digit of the binary number is equal to 1, then figure out the appropriate decimal equivalent for that digit. This is done by taking 2 and raising it to the appropriate power, determined by the length (count) of num minus 1. Sum that with the results of a recursive call to from-binary with all but the first digit of num.
If the first digit is not 1, then just recursively call from-binary with all but the first digit of num.
The book did it a bit differently.
Here is their first version:
|
1
2
3
4
5
6
|
(define (from-binary bits)
(if (empty? bits)
0
(+ (* (first bits) (expt 2 (count (bf bits))))
(from-binary (bf bits)))))
|
I found this bit particularly notable:
|
1
2
|
(+ (* (first bits) (expt 2 (count (bf bits))))
|
They are multiplying first bits and the expt part together, and then summing the result. So when the first digit is 0, that will get multiplied together with the (expt 2 (count (bf bits))) and turn that into 0, so it won’t get added to the total. And when the first digit is 1, the result of expt does get added to the total.
Then they say:
Although this procedure is correct, it’s worth noting that a more efficient version can be written by dissecting the number from right to left. As you’ll see, we can then avoid the calls to
expt, which are expensive because we have to do more multiplication than should be necessary.Suppose we want to find the value of the binary number
1101. Thebutlastof this number,110, has the value six. To get the value of the entire number, we double the six (because1100would have the value 12, just as in ordinary decimal numbers 430 is ten times 43) and then add the rightmost bit to get 13. Here’s the new version:
|
1
2
3
4
5
6
|
(define (from-binary bits)
(if (empty? bits)
0
(+ (* (from-binary (bl bits)) 2)
(last bits))))
|
This version may look a little unusual. We usually combine the value returned by the recursive call with some function of the current element. This time, we are combining the current element itself with a function of the recursive return value. You may want to trace this procedure to see how the intermediate return values contribute to the final result.
The results of trace from-binary with their new version:

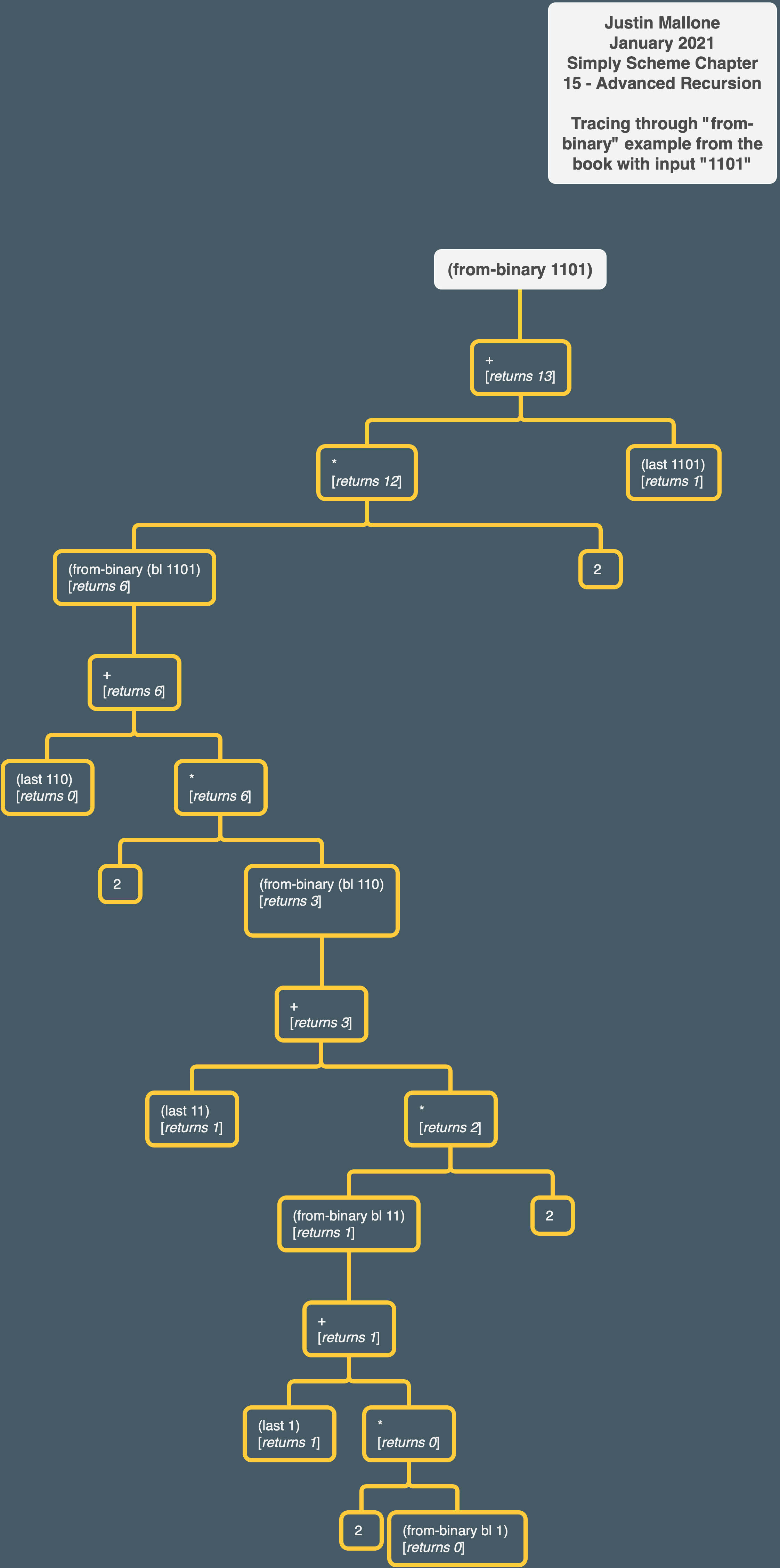
still a bit fuzzy so let me step through the program step by step with the 1101 example.
Ok so let’s say we get to the point where the recursive call to from-binary is going to return 0 because we’ve bl‘ed through the number and we’re down to the 1 that is at the beginning of the number:
|
1
2
3
|
(+ (* (from-binary (bl bits)) 2)
(last bits))))
|
substituting:
|
1
2
3
|
(+ (* 0 2)
1)))
|
and again:
|
1
2
|
(+ 0 1)
|
So the final call recursive call returns 0 and the call “above” that one in the recursive chain of calls returns 1 because of the value of the last digit.

what about when the recursive call is on the first two digits of 1101, 11? Since the recursive call “below” that level returned 1, then by the logic of our program the level “above” that will return 3:
|
1
2
3
|
(+ (* 1 2)
1))))
|
![]()
Now we get to the point where the 0 is the digit that will be returned by last bits. Because the “lower level” of recursive call below this level will return three, and last bits will return 0, this level of our procedure will return 6:
|
1
2
3
|
(+ (* 3 2)
0))))
|
![]()
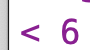
If the original number had been 1111, then this level of the procedure would return 7:

Finally, at the “highest” level of the procedure, since the lower level of recursive call returned 6, and the final digit is 1, the overall procedure will return 13:
|
1
2
3
|
(+ (* 6 2)
1))))
|
Here’s a tree showing this hierarchy stuff visually:
Example – Mergesort
Let’s go back to the problem of sorting a sentence. It turns out that sorting one element at a time, as in selection sort, isn’t the fastest possible approach. One of the fastest sorting algorithms is called mergesort, and it works like this: In order to mergesort a sentence, divide the sentence into two equal halves and recursively sort each half. Then take the two sorted subsentences and merge them together, that is, create one long sorted sentence that contains all the words of the two halves.
This is their half-finished code version of the above:
|
1
2
3
4
5
6
|
(define (mergesort sent)
(if (<= (count sent) 1)
sent
(merge (mergesort (one-half sent))
(mergesort (other-half sent)))))
|
merge is a necessary helper procedure for mergesort.
This is the book’s version of the merge procedure we wrote for exercise 14.15:
|
1
2
3
4
5
6
7
|
(define (merge left right)
(cond ((empty? left) right)
((empty? right) left)
((before? (first left) (first right))
(se (first left) (merge (bf left) right)))
(else (se (first right) (merge left (bf right))))))
|
I won’t explain how this works again since I went into it in some detail before.
Now we have to write
one-halfandother-half. One of the easiest ways to do this is to haveone-halfreturn the elements in odd-numbered positions, and haveother-halfreturn the elements in even-numbered positions. These are the same as the proceduresodds(from Exercise 14.4) andevens(from Chapter 12).
|
1
2
3
4
5
|
(define (one-half sent)
(if (<= (count sent) 1)
sent
(se (first sent) (one-half (bf (bf sent))))))
|
|
1
2
3
4
5
|
(define (other-half sent)
(if (<= (count sent) 1)
'()
(se (first (bf sent)) (other-half (bf (bf sent))))))
|
Example – Subsets
We’re now going to attack a much harder problem. We want to know all the subsets of the letters of a word-that is, words that can be formed from the original word by crossing out some (maybe zero) of the letters. For example, if we start with a short word like
rat, the subsets arer,a,t,ra,rt,at,rat, and the empty word (""). As the word gets longer, the number of subsets gets bigger very quickly.[3]As with many problems about words, we’ll try assuming that we can find the subsets of the
butfirstof our word. In other words, we’re hoping to find a solution that will include an expression like
|
1
2
|
(subsets (bf wd))
|
Let’s actually take a four-letter word and look at its subsets. We’ll pick
brat, because we already know the subsets of itsbutfirst. Here are the subsets ofbrat:
You might notice that many of these subsets are also subsets of
rat. In fact, if you think about it, all of the subsets ofratare also subsets ofbrat. So the words in(subsets 'rat)are some of the words we need for(subsets 'brat).
Here’s a quick tree showing a hierarchy of some subsets of brat excluding the empty word. It doesn’t have stuff that skips over a letter, though (like “brt”).
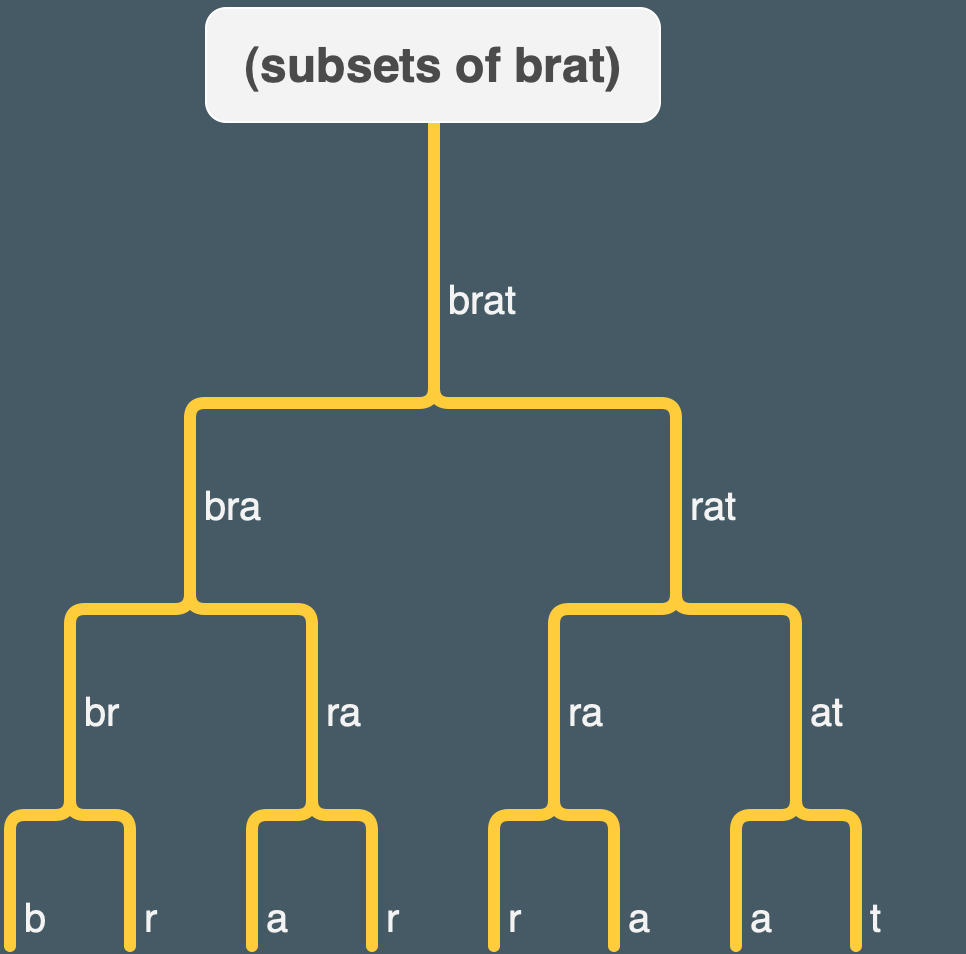
note that there is duplication between subsets (e.g. “ra” or the single letters “a” and “r”).
ADDENDUM: this tree may actually be more relevant for thinking about Exercise 15.3.
Let’s separate those out and look at the ones left over:

Right about now you’re probably thinking, “They’ve pulled a rabbit out of a hat, the way my math teacher always does.” The words that aren’t subsets of
ratall start withb, followed by something that is a subset ofrat. You may be thinking that you never would have thought of that yourself. But we’re just following the method: Look at the smaller case and see how it fits into the original problem. It’s not so different from what happened withdownup.
Now all we have to do is figure out how to say in Scheme, “Put abin front of every word in this sentence.” This is a straightforward example of theeverypattern:
|
1
2
3
4
5
|
(define (prepend-every letter sent)
(if (empty? sent) '()
(se (word letter (first sent))
(prepend-every letter (bf sent)))))
|
The way we’ll use this in
(subsets 'brat)is
|
1
2
|
(prepend-every 'b (subsets 'rat))
|
Of course in the general case we won’t have
bandratin our program, but instead will refer to the formal parameter:
|
1
2
|
(define (subsets wd) ;; first version (se (subsets (bf wd)) (prepend-every (first wd) (subsets (bf wd)))))
|
Ah I see. I think that maybe I was thinking about the program from the wrong angle. I was thinking of breaking down the input word into smaller and smaller subsets (which is kind of what my tree earlier was getting at). But here it seems like we’re building up from the bottom by prepending stuff. E.g. if you have the empty word as the sent for prepend-every and then append t to that, you now have the sentence'(t). And if you have a sentence like '(t "") and then prepend a to each of those elements, then you have '(at a). So the words are getting “built up” as we go along (though there’s the issue of where the empty word is coming from to be prepended to at each step, I’m not clear on that yet but maybe it’s coming).
We still need a base case. By now you’re accustomed to the idea of using an empty word as the base case. It may be strange to think of the empty word as a set in the first place, let alone to try to find its subsets. But a set of zero elements is a perfectly good set, and it’s the smallest one possible.
The empty set has only one subset, the empty set itself. What shouldsubsetsof the empty word return? It’s easy to make a mistake here and return the empty word itself. But we wantsubsetsto return a sentence, containing all the subsets, and we should stick with returning a sentence even in the simple case.[4] (This mistake would come from not thinking about the range of our function, which is sentences. This is why we put so much effort into learning about domains and ranges in Chapter 2.) So we’ll return a sentence containing one (empty) word to represent the one subset.
|
1
2
3
4
|
(define (subsets wd) ;; second version (if (empty? wd) (se "")
(se (subsets (bf wd))
(prepend-every (first wd) (subsets (bf wd))))))
|
Ok, so when subsets has an empty word, it returns the empty word "" in a sentence. And when prepend-every has an empty sentence, it returns the empty sentence.
Still fuzzy on how all this works, so let’s look at an example – (subsets 't).

Let’s step through this.
|
1
2
3
|
> (subsets "")
< '("")
|
This is the result of both recursive calls to subsets in the recursive case. The procedure needs the results of these calls in order to perform further operations. After the recursive calls have been made, and first wd evaluated, the situation is as follows:
|
1
2
3
4
|
(se '("")
(prepend-every 't '(""))
)))
|
OK now I’m starting to get it. The first recursive call to subsets – the one that doesn’t take place within prepend-every – is what gets us the empty word that doesn’t get prepended with the letter “t”. That was something that wasn’t clear to me until now.
When prepend-every gets invoked in the above example, it prepends t to the empty word and returns '(t). prepend-every also has its own recursive call to itself, but it immediately reaches the base case on the input sentence '("") and returns an empty sentence. The empty sentence is the identity element for sentence, and disappears immediately when passed as an argument to se within prepend-every.
This program is entirely correct. Because it uses two identical recursive calls, however, it’s a lot slower than necessary. We can use
letto do the recursive subproblem only once:[5]
|
1
2
3
4
5
6
|
(define (subsets wd)
(if (empty? wd)
(se "")
(let ((smaller (subsets (bf wd))))
(se smaller (prepend-every (first wd) smaller)))))
|
Yeah I definitely see how the let saves work here.
Exercises
✅❌ Exercise 15.1 – to-binary
First Attempt
Write a procedure
to-binary:
|
1
2
3
|
> (to-binary 9)1001
> (to-binary 23)10111
|
I found this really hard for some reason. I think it was partially cuz I had trouble keeping track of the various things I wanted to keep track of in how I wanted to go about solving it and confused myself.
For input ilke 1001, I think the procedure should do something like the following:
- Figure out that 2^3, or 8, is a power of 2 that we need to represent in the binary version as the first “1”
- Figure out that 2^2 and 2^1, or 4 and 2, respectively, are not needed in the binary version and that the values for these numbers in their respective places in the binary system should be “0”
- Figure out that 2^0, or 1, is a power of 2 that we need to represent in the binary version as the final “1”
The first part of step 1 is pretty easy.
|
1
2
3
4
|
(define (power-2-helper num power)
(if (> (expt 2 power) num) (expt 2 (- power 1))
(power-2-helper num (+ 1 power))))
|
This procedure will take a number and return the highest power of 2 (in the form of the plain number – e.g. for 2^3 it will return 8) that does not exceed the number.
The next step should be something like: :
- generate a 1 and subtract the power of 2 from number
- test if the next lowest power of 2 below the previous one is less than the new number. if not, generate a 0, and then test the next lowest power of 2. if so, generate a 1, subtract the new power of 2, and then move onto the next lowest power of 2.
This was an early attempt that was starting to get somewhere, wasn’t quite right though:
|
1
2
3
4
5
6
|
(define (binary-maker num power)
(cond ((= num 0) "")
((> power num) (word 0 (binary-maker num (- power 1))))
(else (word 1 (binary-maker (- num power) (- power 1))))))
|
Here’s where I actually start to get somewhere. This works for the test cases but not for numbers that are actual powers of 2:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
(define (log2 x)
(/ (log x) (log 2)))
(define (power-2-helper num power)
(if (> (expt 2 power) num) (expt 2 (- power 1))
(power-2-helper num (+ 1 power))))
(define (binary-maker num powernum powerexp)
(cond ((= num 0) "")
((> powernum num)
(word 0 (binary-maker num (- powernum (expt 2 (- powerexp 1)))
(- powerexp 1))))
(else
(word 1 (binary-maker (- num powernum) (- powernum (expt 2 (- powerexp 1)))
(- powerexp 1))))
))
(define (to-binary num)
(binary-maker num (power-2-helper num 0) (log2 (power-2-helper num 0) )))
|
This one is getting closer on powers of 2 but has 1 digit too few on them.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
(define (binary-maker num powernum powerexp)
(cond ((and (= num 0)(> powerexp 0))
(word 0 (binary-maker num (- powernum (expt 2 (- powerexp 1)))
(- powerexp 1))))
((= num 0) "")
((> powernum num)
(word 0 (binary-maker num (- powernum (expt 2 (- powerexp 1)))
(- powerexp 1))))
(else
(word 1 (binary-maker (- num powernum) (- powernum (expt 2 (- powerexp 1)))
(- powerexp 1))))
))
|
I wound up changing the > in the first line of the cond to a > and got that to work:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
(define (log2 x)
(/ (log x) (log 2)))
(define (power-2-helper num power)
(if (> (expt 2 power) num) (expt 2 (- power 1))
(power-2-helper num (+ 1 power))))
(define (binary-maker num powernum powerexp)
(cond ((and (= num 0)(>= powerexp 0))
(word 0 (binary-maker num (- powernum (expt 2 (- powerexp 1)))
(- powerexp 1))))
((= num 0) "")
((> powernum num)
(word 0 (binary-maker num (- powernum (expt 2 (- powerexp 1)))
(- powerexp 1))))
(else
(word 1 (binary-maker (- num powernum) (- powernum (expt 2 (- powerexp 1)))
(- powerexp 1))))
))
(define (to-binary num)
(binary-maker num (power-2-helper num 0) (log2 (power-2-helper num 0) )))
|
My intuition is that this is not well organized and fragile and I don’t understand it well, so I’m going to come back to it later after doing some other stuff and try to revise it.
Analysis Regarding Difficulty of Solving This Exercise
Ok some potential problems in my last attempt:
1. Maybe I’m thinking about the problem the wrong way in some fundamental respect
2. Maybe I’m jamming too much into binary-maker (seems likely just by looking at it)
3. I definitely spent too much time “grinding my gears”
4. Not enough thinking, too much “tweak and trace” (“tweak and trace” used to be my default way of trying to write programs. Terrible method. Mostly don’t do it anymore, but still comes up sometimes when I’m stuck)
5. Not looking enough for inspiration from from-binary?
Second Attempt
So let’s think about a new approach. How about:
Based on the result of something like power-2-helper, we figure out how many digits the binary number will have and set the first 1 to “1”, and then subtract the value of that first power of 2 from the number. Then, we “flip” each of 0’s remaining in the number to “1” if the power of 2 that corresponds to them can be subtracted from the remaining number.
My initial stab with this approach was this:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
(define (log2 x)
(/ (log x) (log 2)))
(define (p2 num)
(inexact->exact (floor (log2 num))))
(define (char-generator char num)
(if (= num 0) 0
(word 0 (char-generator 0 (p2 num)))))
(define (initial-binary num)
(word 1 (char-generator 0 (p2 num))))
|
It got me the intermediate result I wanted, e.g. for input of 9 it gives:

Already I’m feeling better about this approach.
Oh btw, I found inexact->exact online, pretty cool procedure.
So with this approach I sort of got somewhere, but still was having trouble with exact powers of 2, and it still seemed overly complicated:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
(define (log2 x)
(/ (log x) (log 2)))
(define (p2 num)
(inexact->exact (floor (log2 num))))
(define (char-generator char num)
(if (= num 0) 0
(word 0 (char-generator 0 (p2 num)))))
(define (next-exp2-down binary)
(expt 2 (- (count binary) 1)))
(define (finish-binary num binary)
(cond
((= num 0) "")
((>= num (next-exp2-down binary))
(word 1
(finish-binary (- num (next-exp2-down binary)) (bl binary))))
(else (word 0 (finish-binary num (bl binary))))))
(define (initial-binary num)
(word 1 (char-generator 0 (p2 num))))
(define (to-binary num)
(finish-binary num (initial-binary num)))
|
I get the correct output for 9 and 23, but for the input 16 I just get “1”.
The functionality at least seems more broken out and better organized, which addresses one of the issues I mentioned.
Third Attempt
Okay now for a different attempt.
Figure out power of 2 that’s below number. Subtract value of power of 2 from number. Then compare values — if next power 2 down is less than the remaining number, generate a 1, and if the next power of 2 down is more than the remaining number, generate a 0:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
(define (log2 x)
(/ (log x) (log 2)))
(define (p2 num)
(inexact->exact (floor (log2 num))))
(define (num-of-next-exp2-down power)
(expt 2 power))
(define (char-generator num power)
(cond ((= num 0) "")
((< power num)
(word 1 (char-generator (- num (num-of-next-exp2-down power))(- power 1))))
(else (word 0 (char-generator num (- power 1))))))
(define (to-binary num)
(char-generator num (p2 num)))
|
Happiest with this attempt so far but it still can’t handle powers of 2.
Fourth Attempt (Success!)
(I’m only giving myself partial credit due to extreme inelegance)
I asked for help in the #technical chat of the Fallible Ideas Discord server:
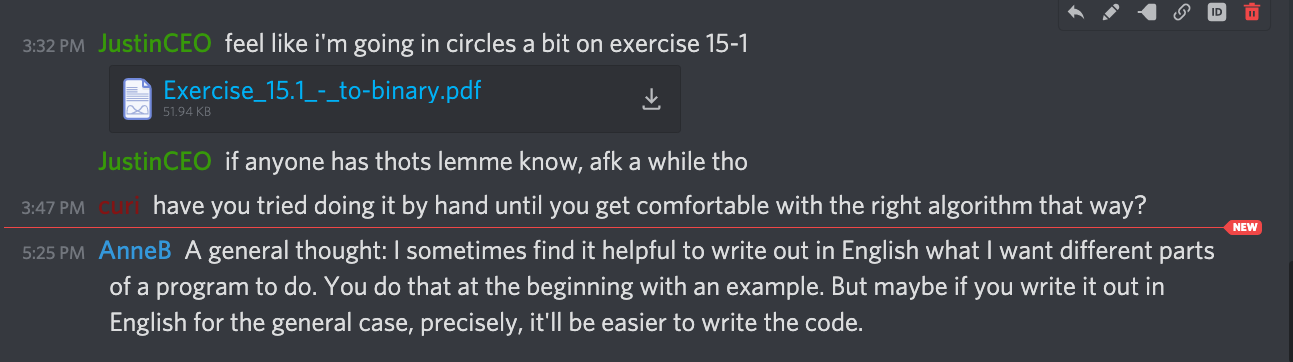
Thanks to AnneB and curi for the advice, it was helpful!
Here is me going through some examples by hand:



And this is my attempt to describe the general case of the problem in English:
to-binary will take a number as input and return a binary version of that number as output. It will call binary-generator with the number and the highest power of 2 that is less than the or equal to the number as arguments.
binary-generator will take a number and power of 2 as input and will return a binary sequence of numbers as output. If the power of 2 is less than or equal to the number, it will invoke “word” with the following arguments: the digit “1” and a recursive call with the difference between the original number and the power of 2, and with 2^(n-1) power of 2. If the number is greater than the power of 2, then the procedure will return “0” and recursively call itself, not decreasing the number but decreasing the power by 1. This will continue until the power of 2 reaches negative 1, at which point the procedure should return "".
The result:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
(define (log2 x)
(/ (log x) (log 2)))
(define (p2 num)
(inexact->exact (floor (log2 num))))
(define (binary-generator num power)
(cond ((= power -1) "")
((<= (expt 2 power) num)
(word 1 (binary-generator (- num (expt 2 power))
(- power 1))))
(else (word 0 (binary-generator num (- power 1))))))
(define (to-binary num)
(if (= num 0) 0
(binary-generator num (p2 num))))
|
I treat 0 as a special case cuz I got errors resulting from log2 otherwise. Having 1 special case seems ok.
Whew, that was a lot of work! 😅
Other People’s Solutions
So it turns out this is way more complicated than it needs to be!
AnneB’s Solution
|
1
2
3
4
5
6
|
(define (to-binary n)
(if (= n 0)
""
(word (to-binary (quotient n 2))
(remainder n 2) )))
|
So let’s see how this works.
If we give it say 9, it will get remainder 9 2, which is 1, and then put the 1 as the second argument to a call to word. The first argument is a recursive call to to-binary with quotient 9 2, which is 4.
The recursive calls generate 0 a couple of times since remainder 4 2 and remainder 2 2, respectively, are both 0. Then when we get down to remainder 1 2, we get the final 1, and then the final recursive call returns a “”. So yeah I think I see how this works.
buntine’s Solution
buntine’s solution is more complex than AnneB’s but simpler than mine:
|
1
2
3
4
5
6
7
8
9
10
|
(define (base-two n)
(if (< n 1)
'()
(se
(if (> (remainder (floor n) 2) 0) 1 0)
(to-binary (/ (floor n) 2)))))
(define (to-binary n)
(accumulate word (reverse (base-two n))))
|
buntine’s base-two procedure plugs a number into remainder (floor n) 2 and checks whether that returns greater than 0. E.g. for 9, remainder (floor 9) 2) returns 1. OTOH, for 4, as in remainder (floor 4) 2), the value returned is 0. If the value returned is greater than 0, 1 is returned as an argument to se. Otherwise, 0 is returned. There is also a recursive call to to-binary with n divided by 2.
The way the program works is pretty interesting. to-binary is accumulating and reversing the values at each stage so the output comes out right. Without the reverse happening at each stage (so if to-binary was just accumulating word) the binary numbers would come out backwards.
Oh but hang on a second, I have an idea:
|
1
2
3
4
5
6
7
8
9
10
|
(define (base-two n)
(if (< n 1)
'()
(se
(to-binary (/ (floor n) 2))
(if (> (remainder (floor n) 2) 0) 1 0))))
(define (to-binary n)
(accumulate word (base-two n)))
|
I improved it 😀
I put the recursive call first within base-two and got rid of the reverse. Hurrah!
Here’s a tree I made of buntine’s original version to understand how it worked:

pongsh’s solution
|
1
2
3
4
5
|
(define (to-binary num)
(cond ((= num 0) 0)
((= num 1) 1)
(else (word (to-binary (floor (/ num 2))) (modulo num 2)))))
|
This is pretty similar to the last one in some ways but more elegant. It’s got the recursive call with (to-binary (/ (floor n) 2)) and is generating the 1 or 0 to use for a given number using modulo num 2.
✅ Exercise 15.2
A “palindrome” is a sentence that reads the same backward as forward. Write a predicate
palindrome?that takes a sentence as argument and decides whether it is a palindrome. For example:
|
1
2
3
4
5
6
7
8
|
> (palindrome? '(flee to me remote elf))
#T
> (palindrome? '(flee to me remote control))
#F
|
Do not reverse any words or sentences in your solution.
Here’s my solution. I’m using accumulate since they didn’t put any restrictions on the solution method besides not using reverse.
|
1
2
3
4
5
6
7
8
9
|
(define (palindrome-helper wd)
(cond ((<= (count wd) 1) #t)
((not (equal? (first wd)(last wd))) #f)
(else (palindrome-helper (bl (bf wd))))))
(define (palindrome? sent)
(palindrome-helper (accumulate word sent)))
|
The only semi-tricky part was realizing that I had to turn the result of UPDATE: AnneB pointed out that this doesn’t actually make sense so I struck it out and updated/simplified my procedure accordingly.accumulate word sent into a word in order for my helper procedure to operate on it correctly.
✅ Exercise 15.3
Write a procedure
substringsthat takes a word as its argument. It should return a sentence containing all of the substrings of the argument. A substring is a subset whose letters come consecutively in the original word. For example, the wordbatis a subset, but not a substring, ofbrat.
First Solution, Using Remdup
My solution, which uses remdup from exercise 14.3:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
(define (remdup sent)
(cond ((empty? sent) '())
((member? (first sent) (bf sent))
(remdup (bf sent)))
(else (se (first sent) (remdup (bf sent))))))
(define (substrings-helper wd)
(if (empty? wd) '()
(se wd (substrings (bf wd))(substrings (bl wd)))))
(define (substrings wd)
(remdup (substrings-helper wd)))
|
The tree I made earlier when I was trying to understand subsets is actually relevant:
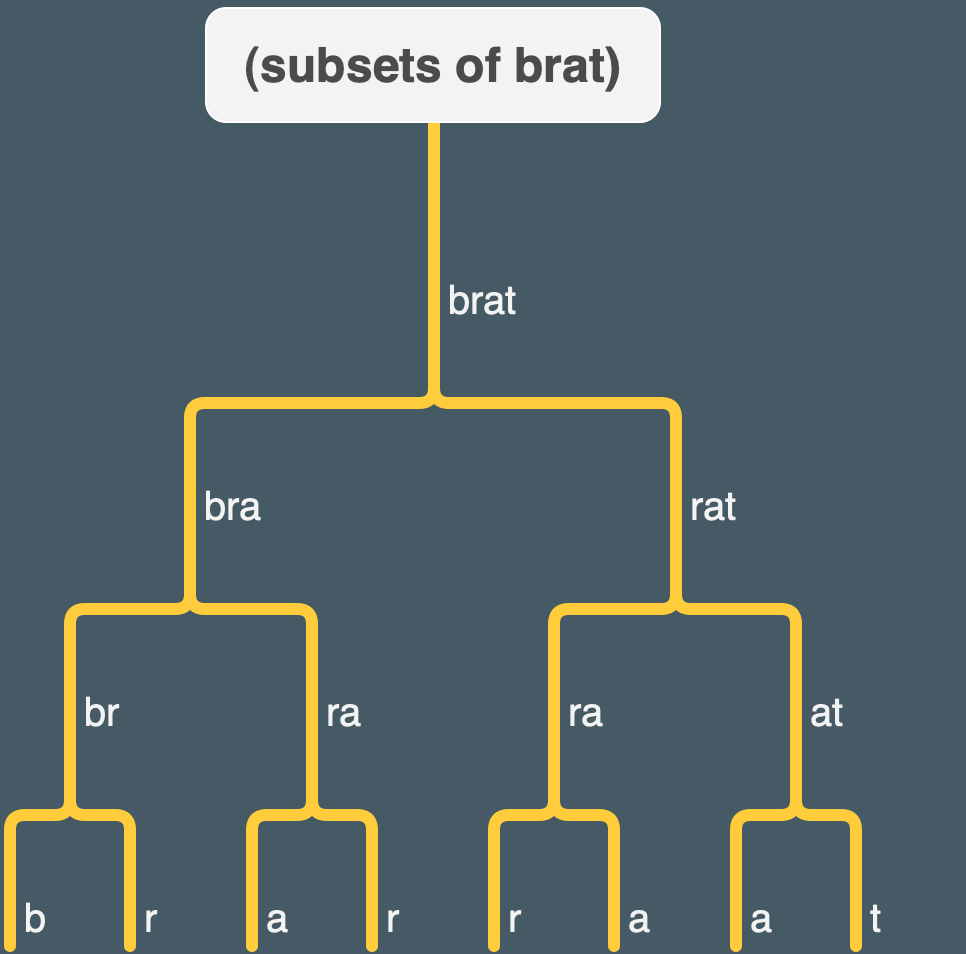

This has duplicates (e.g. “ra” and various single letters). We don’t want those, so we use remdup to clean things up.
This is probably more computationally expensive than it needs to be, and maybe there is a better way to do it. It was very easy for me to understand and figure out though (it probably helped that I accidentally partly figured out this program while trying to deal with subsets earlier).
Attempting Another Solution
After working through the first exercise with the help of curi and Anne’s advice, and then glancing briefly at some other solutions and seeing that they looked very different, I thought I’d try coming up with another solution to this problem.
The procedure should take a word as an argument. It should figure out the length of the word, and then go through the word N–sized chunks at a time, from left to right, where N starts with the value of the length of the word and then decreases by one with each successive pass. The results of this passing through the word in and size chunks it should be grouped together into a sentence, and the passing through the word should continue until N reaches zero.
Since substrings is only supposed to take the word itself, the bulk of the operational work of the procedure will take place within a helper procedure.
There are a couple of sub problems that need to be solved in order for the procedure to work in the way that I’ve described. The first problem is that we need someway to only select a specific range of characters. The second some problem is that we need someway to pass through the word from left to right and then stop when we reach The point at which where as far right as we can go within the word while still having the number of characters that we need in that particular pass through the word.
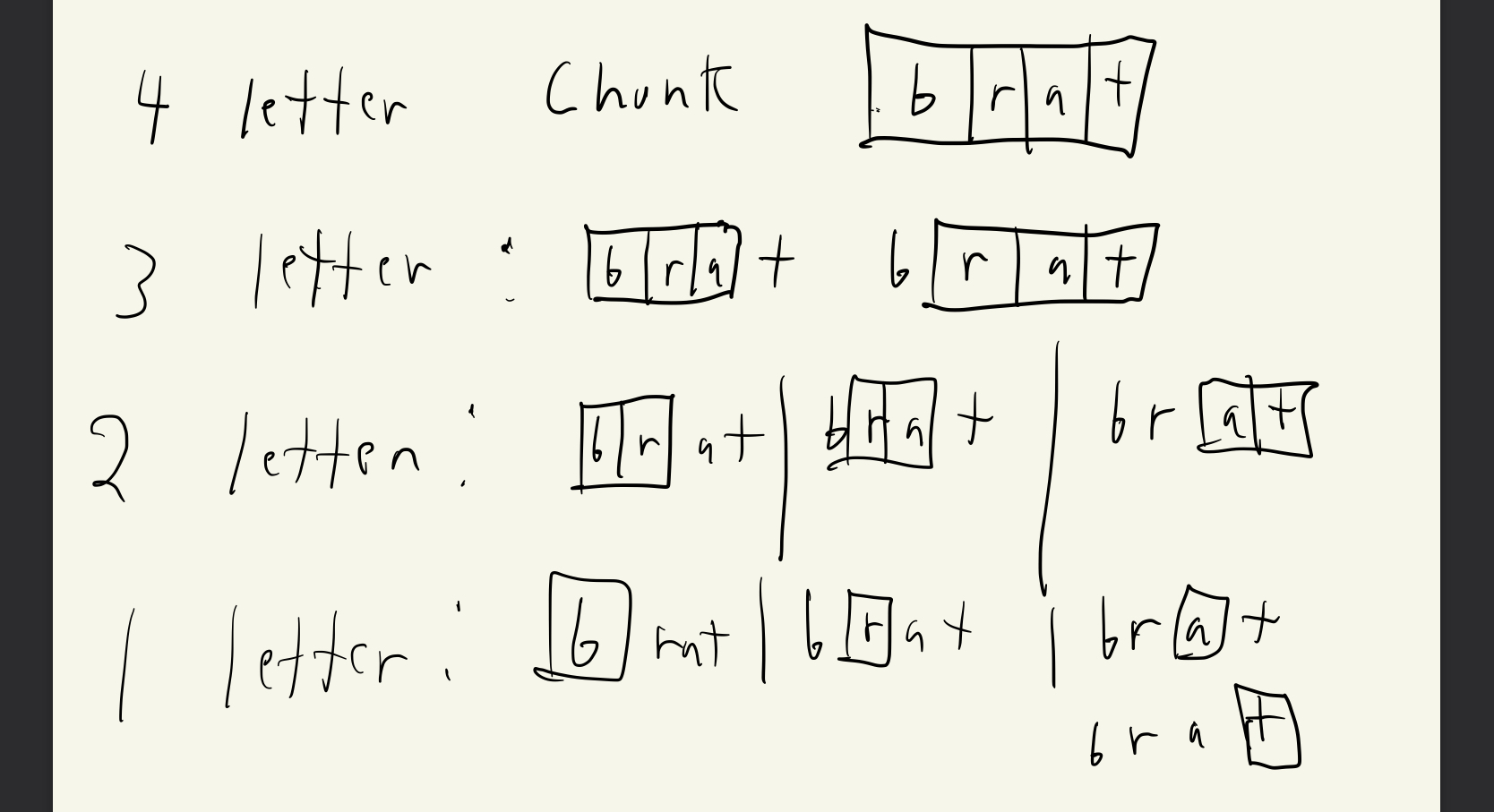
Some notes: the amount of spaces that you need to scroll through the word is the same as the difference between the length of the original word and the current chunk size.
The number of chunks at a particular level increases by one as the chunk size goes down by one.
I tried making a very manual version of the program I was envisioning to see what it was like, specifically handling a case of four-letter input:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
(define (four-word-chunks wd)
(se wd))
(define (three-word-chunks wd)
(se (bl wd)
(bf wd)))
(define (two-word-chunks wd)
(se (bl (bl wd))
(bl (bf wd))
(bf (bf wd))))
(define (one-word-chunks wd)
(se (bl (bl (bl wd)))
(bl (bl (bf wd)))
(bl (bf (bf wd)))
(bf (bf (bf wd)))))
(define (substrings wd)
(se (four-word-chunks wd) (three-word-chunks wd) (two-word-chunks wd) (one-word-chunks wd)))
|
I had some difficulty seeing how I’d generalize this, so I started to wonder if I should take a new approach.
I persisted, and after some thinking and testing, managed to come up with this solution which worked but not in the way I wanted:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
INCORRECT
(define (bln n)
(repeated bl n))
(define (bfn n)
(repeated bf n))
(define (chunk wd chunksize place)
(cond ((= (count wd) chunksize) wd)
((> place chunksize) '())
(else
(se
((bfn place)
((bln (- chunksize place))
wd))
(chunk wd chunksize (+ 1 place))))))
(define (substring-helper wd chunksize)
(if (= chunksize 0) '()
(se (chunk wd chunksize 0)
(substring-helper wd (- chunksize 1)))))
(define (substrings wd)
(substring-helper wd (count wd)))
|
I want to note that it was at the stage of writing my detailed explanation of what each step of the procedure does (and reviewing the output from running trace in the course of doing so) that I realized that the procedure was operating differently than I intended. So I had a major misconception about how my procedure worked despite 1) having written down what I was trying to accomplish beforehand and 2) having output which made it looked like I’d solved the problem! 🤯 I thought this was notable – how I could have a misconception like this and only catch it at a fairly late stage. Better than not catching it at all 🙂
Second Solution
After some thinking and figuring out what was going wrong, I came up with this:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
(define (charsel wd count)
(if (= count 0) ""
(word (first wd)(charsel (bf wd)(- count 1)))))
(define (chunk wd chunksize place)
(if (> (+ place chunksize)(count wd)) '()
(se
(charsel ((repeated bf place) wd) chunksize)
(chunk wd chunksize (+ 1 place)))))
(define (substring-helper wd chunksize)
(if (= chunksize 0) '()
(se (chunk wd chunksize 0)
(substring-helper wd (- chunksize 1)))))
(define (substrings wd)
(substring-helper wd (count wd)))
|
substrings itself invokes substring-helper with the wd and the count wd as arguments.
substring-helper is a fairly straightforward recursive procedure. If chunksize (the size of the chunks we want in the current procedure) is 0, we return the empty sentence. Otherwise, we invoke sentence with a call to the chunk procedure and a recursive call to substring-helper as arguments. The recursive call to substring-helper reduces the chunksize by 1.
chunk is where the interesting action in this procedure happens. The chunk procedure, in addition to having arguments for wd and chunksize, also has an argument for place. The place argument represents the number of digits between the start of the word and the beginning of the chunk in the current “pass” through the word. That’s why the call to chunk from within substring-helper starts place at 0 – we start gathering our chunks at the beginning of the word, and then with each recursive call to chunk we increase place by 1, and that moves the beginning of the next chunk over “one to the right”, and so on, until we’ve gotten each substring of a particular length. So the recursive calls to chunk generate the chunks for a particular length (say, 2 word chunks in a 4 letter word) and then substring-helper is responsible for making that all the lengths get generated.
This line…
|
1
2
|
(if (> (+ place chunksize)(count wd)) '()
|
…ensures that the chunk procedure stops and return the empty sentence when the combination of chunk and place exceed the size of the word. This is to ensure that the procedure doesn’t try to go “off the word” in collecting chunks, which would lead to an error. E.g. if you’re collecting two word chunks on the word “chat”, for the first chunk you’ll get “ch” when the place value is 0, and for the second chunk you’ll get “ha” when the place value is 1, and for the final chunk you’ll get “at” when the place value is 2. At this point, the sum of the place value and the chunk size is 4, which is the same as the word. If the program kept continuing on past this point, then it would try to grab a 2 letter chunk starting at the “t” of chat and at that point would hit an error.
I use repeated bf with the place value to actually move the “starting place” from left to right through the word. I also made a procedure, charsel, to actually select the characters. It takes a segment of the word (adjusted for starting place) and the chunksize as arguments and then selects the first character of the word while recursively calling itself and reducing the counter by 1.
Here’s the chunk part of my procedure in action with trace chunk provided the output in light purple:

Other People’s Solutions
AnneB’s Solution
|
1
2
3
4
5
6
7
8
9
10
11
12
|
(define (substrings w)
(if (= (count w) 1)
(sentence w)
(substrings-helper (first w) (second w) (substrings (butfirst w))) ))
(define (substrings-helper f s sent)
(if (empty? sent)
(sentence f)
(if (equal? (first (first sent)) s)
(sentence (first sent) (word f (first sent)) (substrings-helper f s (butfirst sent)))
(sentence (first sent) (substrings-helper f s (butfirst sent))) )))
|
Let’s walk through this.
For substrings, if count w equals 1, then sentence is invoked on w. Otherwise, substrings-helper is called with the first and second letters of word and another call to substrings as arguments. The other call to substrings is given butfirst w as its argument.
For substrings-helper, if sent (a call to substrings-helper) is empty, then a sentence is returned with f.
If the first letter of the first word of sent is equal to s, then a sentence is returned with first sent and a word made of f and first sent, and also, within that sentence being returned, there is a recursive call to substrings-helper.
Otherwise, a sentence is returned with first sent and a recursive call to substrings-helper. So the word made form f and first sent is missing.
I am finding the mechanics here a bit hard to follow. Let’s see what the trace looks like for “rat” as the input word:

While I have a vague idea of what’s going on, I’m still finding the details a bit difficult to follow, so I’m going to set this aside for now.
buntine’s Solution
|
1
2
3
4
5
6
7
8
9
10
|
(define (diminish wd)
(if (empty? wd)
'()
(se wd (diminish (bl wd)))))
(define (substrings wd)
(if (empty? wd)
(se "")
(se (diminish wd) (substrings (bf wd)))))
|
This one I found easier to understand.
diminish takes a word and returns that word and does bl through the word, return the word at each step (e.g. for input word rat diminish will return rat, ra, r.) When the word is empty diminish returns the empty sentence.
substrings puts the results from diminish in a sentence and then recursively calls substrings with the bf of the word, which creates a new chain of calls to diminish for each bf of the word. So for rat, the procedure will first generate the rat ra r result like I said, and then diminish winds up getting run on at, which generates at a, and so on. By this method it goes through each substring of the word and does so only once. By the way, if you don’t want the empty word as output, it seems like you can change the se "" line to se '() with no negative consequences.
I made a tree to help me understand this one and found it helpful. By the way, MindNode users, if you have an image in your copy-paste buffer, you can paste it directly into a node by selecting the node and hitting cmd-v (on macOS).

✅ Exercise 15.4
Write a predicate procedure
substring?that takes two words as arguments and returns#tif and only if the first word is a substring of the second. (See Exercise 15.3 for the definition of a substring.)
Be careful about cases in which you encounter a “false start,” like this:
|
1
2
3
|
> (substring? 'ssip 'mississippi)
#T
|
and also about subsets that don’t appear as consecutive letters in the second word:
|
1
2
3
|
> (substring? 'misip 'mississippi)
#F
|
Trivial Solution
Here’s a trivial solution assuming you’ve solved 15.3 correctly:
|
1
2
3
|
(define (substring? sub wd)
(member? sub (substrings wd)))
|
First Attempt at a Non-Trivial Solution (failed)
Here was my first idea for a more complicated solution:
- Check the letter of the first word against the first letter of the second word. If it matches, recursively call the checking procedure with the
bfof both words. - If the first word becomes empty before you run out of characters in the second word, return #t.
- If the second word runs out of characters before the first, return #f
- Otherwise, recursively call the checking procedure with the original word as the word you are checking (“resetting” the word you are checking to the original word after a failure to find a match) and with
bfof the second word.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
(define (substring-helper currsub origsub wd)
(cond ((empty? currsub) #t)
((empty? wd) #f)
((equal? (first currsub)
(first wd))
(substring-helper (bf currsub) origsub (bf wd)))
(else (substring-helper origsub origsub (bf wd)))))
(define (substring? sub wd)
(substring-helper sub sub wd))
|
This did not work. It ran into one of the problems from the book examples. See the image below for the line that indicates the problem:
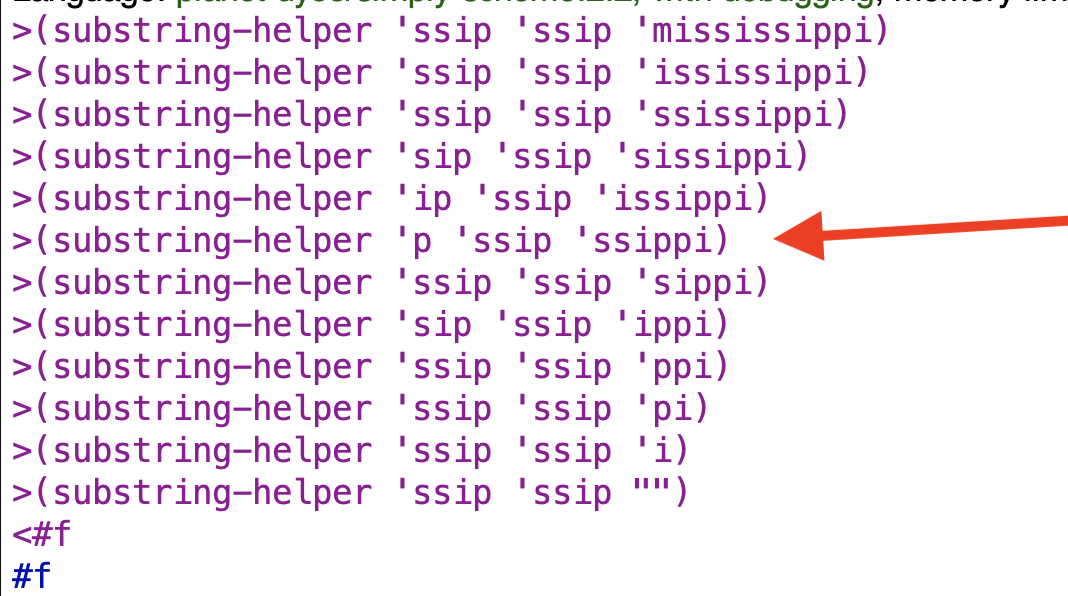
The problem is that currsub doesn’t reset soon enough after the “false start” of mississippi and so misses the match for ssip.
Second Attempt at a Non-Trivial Solution (Success)
I decided to try a different approach incorporation one of the helper procedures from my previous solution in 15.3. The basic idea is this: generate subsegments of the second word equal in length to the substring (the first word) you’re trying to find a match for. If no match is found, do the same process but on bf of the second word. Keep going until you find a match (in which case you return true) or the length of the first word exceeds the length of the second (at which point a match becomes impossible and you should return false).
The implementation:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
(define (charsel wd count)
(if (= count 0) ""
(word (first wd)(charsel (bf wd)(- count 1)))))
(define (substring-helper sub wd)
(cond ((> (count sub) (count wd)) #f)
((equal?
(charsel wd (count sub))
sub) #t)
(else (substring-helper sub (bf wd)))))
(define (substring? sub wd)
(substring-helper sub wd))
|
You can see the difference in operation below:
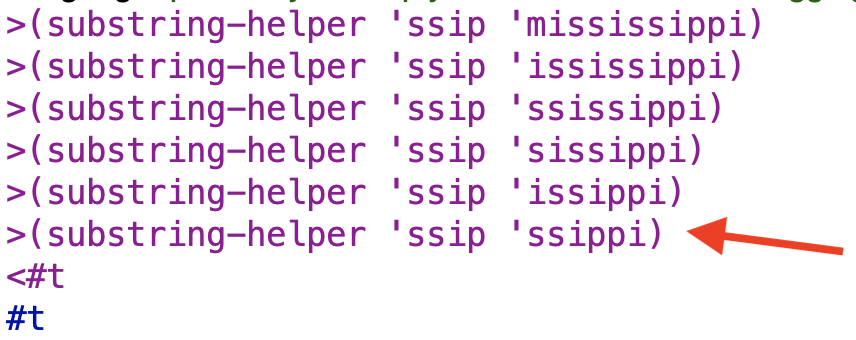
the same sub is being tested against the first four letters of the ever-shortening second word each time, so ultimately we get a true result.
✅ Exercise 15.5
Suppose you have a phone number, such as 223-5766, and you’d like to figure out a clever way to spell it in letters for your friends to remember. Each digit corresponds to three possible letters. For example, the digit 2 corresponds to the letters A, B, and C. Write a procedure that takes a number as argument and returns a sentence of all the possible spellings:
(We’re not showing you all 2187 words in this sentence.) You may assume there are no zeros or ones in the number, since those don’t have letters.
Hint: This problem has a lot in common with the subsets example.

Already so suppose we just gave it “2”. We’d want it to return A, B, and C.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
(define (prepend-every letter sent)
(if (empty? sent) '()
(se (word letter (first sent))
(prepend-every letter (bf sent)))))
(define (phone-letters digit)
(cond ((equal? 2 digit) '(a b c))
(else "")))
(define (phone-spell num)
(if (empty? num) '()
(se (phone-spell (bf num))
(phone-letters (first num)) (phone-spell (bf num)))
))
|
This very minimal procedure gets us that far, but obviously we want way more functionality 🙂

If we just add a line in phone-letters for the 3 digit, we get this result:
![]()
If we want to get to the point of handling 2-digit numbers, we need to have some sort of way of prepending things like the book people did in subsets.
So what we want is to get say the letters for 2, '(a b c).“, and the letters for 3, (d e f). And then we want to return a sentence that’s like:
(ad ae af bd be bf cd ce cf).
So what’s this sentence made out of?
It goes through each value of the (a b c) sentence and prepends it to the values for the (d e f) sentence. So first it prepends a to each element of (d e f), and then does the same with b and c.
So we’ll need some way to take two sentences and generate such a list. The following procedure accomplishes that goal by building on prepend-every.
|
1
2
3
4
5
|
(define (prepend-sentence sent1 sent2)
(if (empty? sent1) '()
(se (prepend-every (first sent1) sent2)
(prepend-sentence (bf sent1) sent2))))
|

Let’s try using it:
|
1
2
3
4
5
6
|
(define (phone-spell num)
(if (empty? num) (se "")
(se (phone-spell (bf num))
(prepend-sentence (phone-letters (first num)) (phone-spell (bf num)))
)))
|
![]()
Hmm. So we’re getting there but there are two problems:
- We don’t want the single digit values
- We don’t want the empty word
I reorganized my program a bit and added a couple of helper procedures and a keep:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
(define (atleast wd)
(lambda (sent-wd) (>= (count sent-wd) (count wd))))
(define (phone-spell-helper num)
(if (empty? num) (se "")
(se (phone-spell (bf num))
(prepend-sentence (phone-letters (first num)) (phone-spell (bf num)))
)))
(define (phone-spell num)
(keep (atleast num)(phone-spell-helper num)))
|
atleast takes some word (such as the initial numeric sequence) as an argument and returns a procedure that checks whether a value provided by a higher order procedure is at least as long as the input to atleast. In combination with keep, it ensures that any values that are kept from the sentence that results from running phone-speller-helper are at least as long as the original input number.
Here’s the full, completed program:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
(define (atleast wd)
(lambda (sent-wd) (>= (count sent-wd) (count wd))))
(define (prepend-every letter sent)
(if (empty? sent) '()
(se (word letter (first sent))
(prepend-every letter (bf sent)))))
(define (prepend-sentence sent1 sent2)
(if (empty? sent1) '()
(se (prepend-every (first sent1) sent2) (prepend-sentence (bf sent1) sent2))))
(define (phone-letters digit)
(cond ((equal? 2 digit) '(a b c))
((equal? 3 digit) '(d e f))
((equal? 4 digit) '(g h i))
((equal? 5 digit) '(j k l))
((equal? 6 digit) '(m n o))
((equal? 7 digit) '(p q r s))
((equal? 8 digit) '(t u v))
((equal? 9 digit) '(w x y z))
(else "")))
(define (phone-spell-helper num)
(if (empty? num) (se "")
(se (phone-spell (bf num))
(prepend-sentence (phone-letters (first num)) (phone-spell (bf num)))
)))
(define (phone-spell num)
(keep (atleast num)(phone-spell-helper num)))
|
I ran this:
|
1
2
|
(count (phone-spell 2235766))
|
…and get a different result than the book’s 2187; instead I get 2916. I think the book people are using a different set of mappings of digits to letters for whatever their equivalent of phone-letters is. I initially got 2187 but then added a letter to the sentence for digit 7 that was missing and I got the 2916 that other solutions got.
Other People’s Solutions
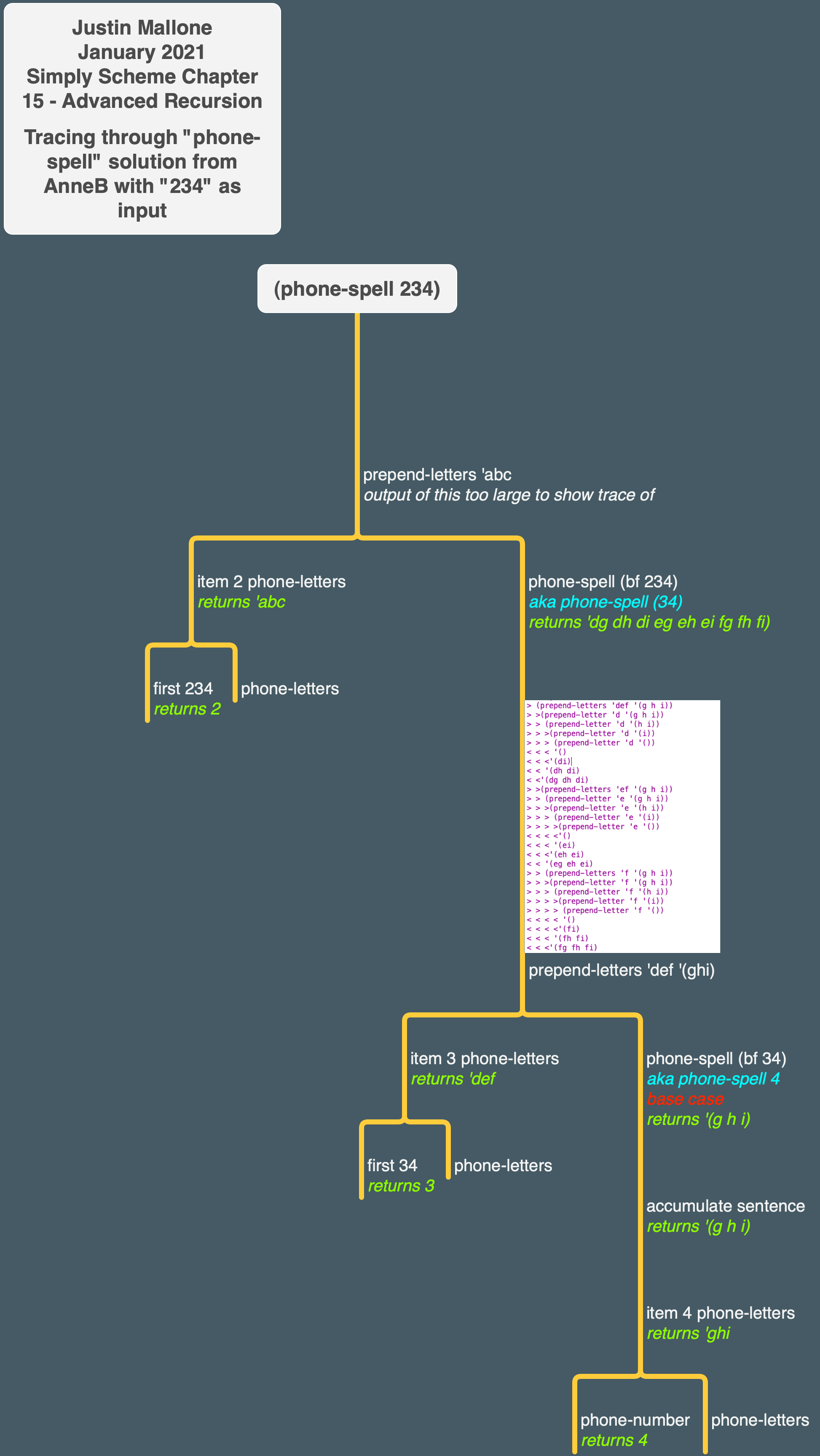
AnneB
Let’s go through it. prepend-letter and prepend-letters are pretty similar to my prepend-every and prepend-sentence. phone-spell is notably different though:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
(define (phone-letters)
'("" ABC DEF GHI JKL MNO PQRS TUV WXYZ))
(define (prepend-letter letter sent)
(if (empty? sent)
'()
(sentence (word letter (first sent))
(prepend-letter letter (butfirst sent)))))
(define (prepend-letters letters sent)
(if (empty? letters)
'()
(sentence (prepend-letter (first letters) sent)
(prepend-letters (butfirst letters) sent))))
(define (phone-spell phone-number)
(if (= (count phone-number) 1)
(accumulate sentence (item phone-number (phone-letters)))
(prepend-letters (item (first phone-number) (phone-letters))(phone-spell (butfirst phone-number)))))
|
So the base case is if the count of phone-number equals 1. You have to cut it off before the count gets to 0 or else you’ll get errors when trying to use item. In that case, a sentence is accumulated out of the letters in phone-letters that match that single number. For example, for the number 3 you get '(g h i)
![]()
If the count of phone-number is greater than 1, prepend-letters is invoked with (prepend-letters (item (first phone-number) (phone-letters)) (phone-spell (butfirst phone-number))))).
Here’s an example trace of running prepend-letters:

In this manner all the relevant letter sequences are generated.
I made a tree in order to understand how Anne solved her version. That tree is below:
I should have used item for phone-letters like AnneB did. I’ve used item for similar purposes before but defaulted back to a big cond here.
✅ Exercise 15.6
Let’s say a gladiator kills a roach. If we want to talk about the roach, we say “the roach the gladiator killed.” But if we want to talk about the gladiator, we say “the gladiator that killed the roach.”
People are pretty good at understanding even rather long sentences as long as they’re straightforward: “This is the farmer who kept the cock that waked the priest that married the man that kissed the maiden that milked the cow that tossed the dog that worried the cat that killed the rat that ate the malt that lay in the house that Jack built.” But even a short nested sentence is confusing: “This is the rat the cat the dog worried killed.” Which rat was that?
Write a procedureunscramblethat takes a nested sentence as argument and returns a straightforward sentence about the same cast of characters:
|
1
2
3
4
5
6
7
8
|
> (unscramble '(this is the roach the gladiator killed))
(THIS IS THE GLADIATOR THAT KILLED THE ROACH)
> (unscramble '(this is the rat the cat the dog the boy the girl saw owned chased bit))
(THIS IS THE GIRL THAT SAW THE BOY THAT OWNED THE DOG THAT CHASED THE CAT THAT BIT THE RAT)
|
You may assume that the argument has exactly the structure of these examples, with no special cases like “that lay in the house” or “that Jack built.”
Attempting the Solution
This is sort of getting towards the right output but not quite:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
(define (bfn n input)
((repeated bf n) input))
(define (second input)
(first (bf input)))
(define (unscramble sent)
(cond ((<= (count sent) 1) '())
((and
(equal? (first sent) 'this)
(equal? (second sent) 'is))
(se '(this is) (unscramble (bfn 2 sent))))
((equal? (first sent) 'the)
(se (unscramble (bfn 2 sent)) 'that (last sent) (first sent) (second sent)))))
|
|
1
2
|
'(this is that killed the gladiator that killed the roach)
|
Already let’s try talking this out in English with the gladiator/roach case.
input:
|
1
2
|
(this is the roach the gladiator killed))`
|
I want to get to this:
|
1
2
|
(THIS IS THE GLADIATOR THAT KILLED THE ROACH)
|
So the gladiator is VERBing the first thing.
I think the basic structure we want is this: if a sentence starts with “this is”, we grab the first thing after the “this is” (here, “the roach”) and put it at the end, and then we recursively call unscramble without the first thing.
|
1
2
3
4
5
|
((and
(equal? (first sent) 'this)
(equal? (second sent) 'is))
(se '(this is) (unscramble (bfn 4 sent)) (third sent) (fourth sent)))
|

Hey we’re starting to get close!
And then if a sentence doesn’t start with “this is”, but instead starts with “the”, we take the first two words + 'that plus the last word, put that on the end, and then do another recursive call to unscramble with like (bl (bf (bf sent)))).
|
1
2
3
|
((equal? (first sent) 'the)
(se (unscramble (bl (bfn 2 sent))) (first sent) (second sent) 'that (last sent) )))
|

ah-ha!

😀
Full Solution
Full program. I changed the base case to (= (count sent) 0) cuz I didn’t see a need to include the case where sent = 1. I think the reason is that since we’re assuming all the input will be in a certain format, we’ll always wind up with 0. “this is the x” is a 4 word chunk which my first recursive case addressed, and the other cases are all “the x” + a verb, which is a 3 word chunk my second case addresses. All properly formatted input sentences will be some combination of a 4 word chunk plus a group of 3 word chunks (e.g. “this is the roach” + “the gladiator killed”, or “this is the rat” plus “the cat … bit” and “the dog…chased” and so on). So we’ll always get to 0, so that’s the only case I need to worry about.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
(define (bfn n input)
((repeated bf n) input))
(define (second input)
(first (bf input)))
(define (third input)
(first (bf (bf input))))
(define (fourth input)
(first (bf (bf (bf input)))))
(define (unscramble sent)
(cond ((= (count sent) 0) '())
((and
(equal? (first sent) 'this)
(equal? (second sent) 'is))
(se '(this is) (unscramble (bfn 4 sent)) (third sent) (fourth sent)))
((equal? (first sent) 'the)
(se (unscramble (bl (bfn 2 sent))) (first sent) (second sent) 'that (last sent) ))))
|
Other People’s Solutions
AnneB broke out dealing with the middle of the sentence into a separate procedure rather than dealing with it all in one procedure. I think that organization is better. She also assumed the formatting of the sentence rather than testing. I think that makes sense.
buntine did a totally different approach, where he appears to have extracted the elements of the sentence and reassembled them. I haven’t looked in detail at it but I liked the general idea. Note his procedure is mislabeled: by nouns he actually means verbs.